
When AMD released the RDNA and Radeona RX 5000 architecture in the summer of 2019, it looked like major changes after eight years, at least for five years, and new generations will add CU / SP (Compute Units / Stream Processors) and make minor improvements. optimization for watt output and support for new technologies.
The release of Radeon RX 6000s with RDNA 2 architecture has already broken this rather anticipated idea. They have brought the so-called Infinity Cache, a large last-level cache that reduces access to graphics memory, allowing AMD to install a full high-end 256bit bus combined with last-generation memories (GDDR6) and as a result achieve the performance for which the competition needs a 384bit bus and a more expensive / energy-intensive GDDR6X. After many years, AMD managed to surprise Nvidia a bit, which for the first time used the most powerful GPU of the given generation (Gx102) instead of the second most powerful GPU (Gx104) on GeForce x800 series cards.
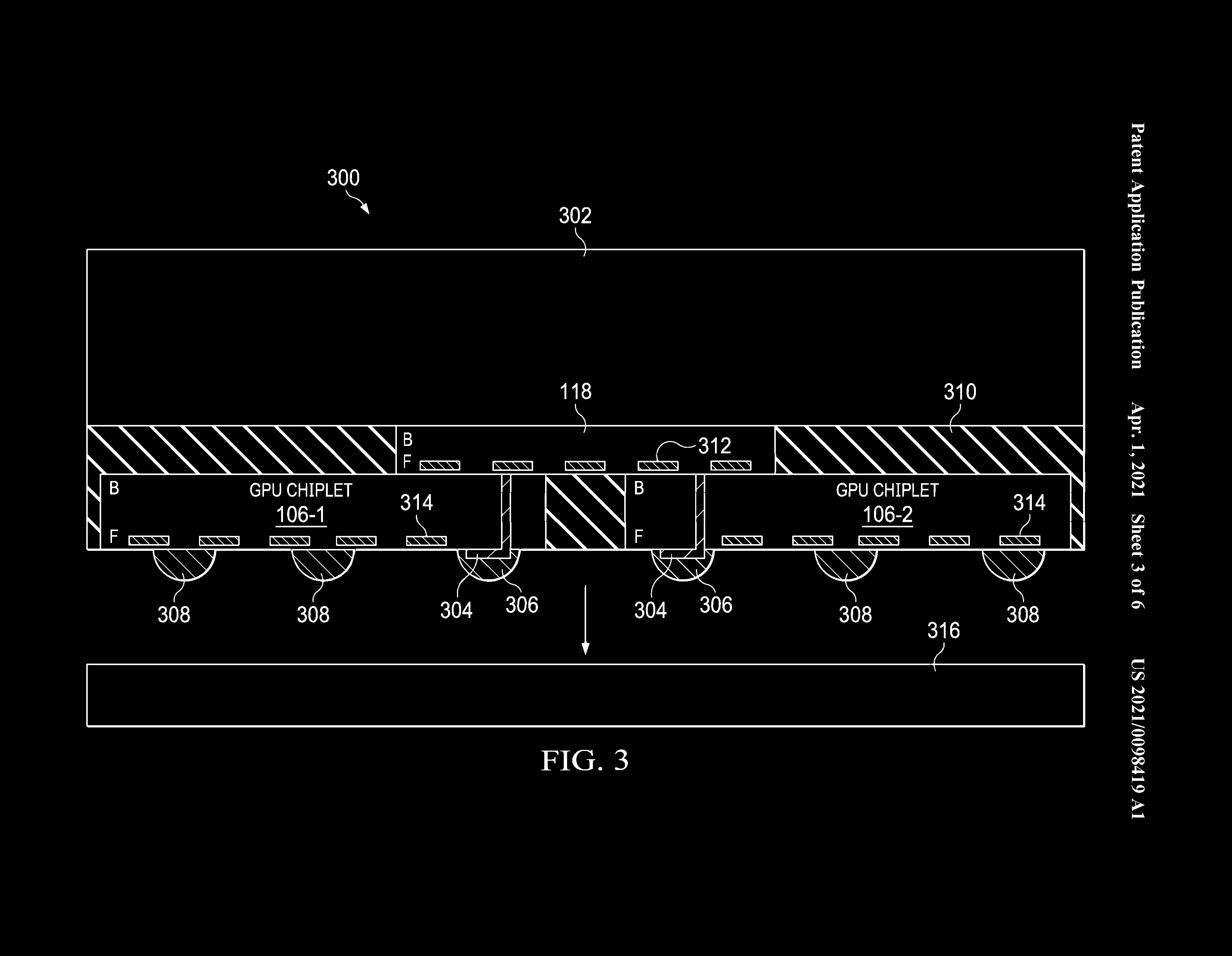
AMD’s RDNA seemed to address primarily energy efficiency, RDNA 2 decided to solve memory throughput, and RDNA 3 was going to solve the problems associated with large monolithic GPUs by splitting them into chipsets. Current rumors, however, suggest that such a view of RDNA 3 would be considerably narrower.
Relatively reliable leaks such as Greymon55 and Yuko Yoshida suggest that RDNA 3 will bring significant changes at the front-end and back-end levels of the graphics chip, as well as an overall reworking of the graphics core function block structure. These words were understood by most sources to be arranged differently in CUs (computational blocks), specifically 3 CUs (with 32 stream processors as in RDNA 2) were spoken on WGP, which is probably not accurate. Leaker Bondrewd indicated that RDNA 3 no longer has a CU. This would mean that the arrangement of stream processors in (to some extent) separate blocks of 64 (GCN) and 32 (RDNA), respectively, is a thing of the past. If you can read between the lines, it looks like the RDG 3 Work Group Processor (WGP) will be eight SIMD units with a width of 32 and an unknown number of texturing units. Perhaps this could be lower (half?) In relation to stream processors than with current architectures.
Without further information, it is not possible to say with certainty where AMD is heading, but it may be an effort to further reduce latencies or (despite more complex scheduling) to further increase overall efficiency (which outweighs the cost of transistors providing more complex scheduling). Furthermore, it is possible that some of these changes will be due to the division of the GPU into chipsets, so it can be assumed that they will be present only in the chips. Navi 31 a Navi 32which are chiplet and not in Navi 33 a Navi 34which are monolithic.
With this generation, AMD is changing virtually all architectural aspects from the physical division of silicon into chipsets through the reorganization of functional blocks in chipsets to control and load distribution within the chip (flight). To this end, we should expect a significant shift in efficiency per power per watt, without which AMD’s performance targets would not be possible and the deployment of two new production processes (5nm and 6nm TSMC).

When it comes to performance goals, it seems that such a portion of changes is not the result of anything other than the announced goal of increasing the intergenerational performance of the high-end to 2.5-2.7 times. The changes described make it somewhat easier to understand how 15360 stream processors could be integrated into the GPU instead of the previously expected 10240 (for example, there is some chance that WGP will carry half the number of texturing units than the ratio of current architectures, leading to some transistor and area savings). At the same time, the presence of 15360 stream processors would better explain a performance target close to three times 5120 stream processors Navi 21, despite the fact that the 5nm process reduces the consumption by only 30% compared to 7nm (at the same beats), so there would probably be no room for such a beat increase that with 2x more stream processors, 2.5x more power could be achieved. However, if 2.5-2.7 times more power is to be achieved with 3 × more stream processors, there is also room for reducing the clock frequencies, which would enable the achievement of an ambitious goal even with a 5nm process, which does not help consumption much in itself.
Perhaps even more curious are rumors that AMD plans to achieve this goal still with 256bit bus, while memory access requirements will be reduced by 512MB Infinity Cache (4x higher capacity compared to RDNA 2 / Navi 21 / Radeon RX 6800 / RX 6900) . However, this report still lacks confirmation from multiple independent sources.
–


{kind=link}