subtlety
2024-10-17 12:38:27 Source: Qubits
Improved performance but cheaper inference
Mingmin comes from Aofei Temple
Qubits | Public account QbitAI
Meta version o1 is also here.
Tian Yuandong’s team brings new workDualformerseamlessly combining fast and slow thinking, improving performance and lowering costs.
Can solve complex problems such as mazes and push boxes.

By having the model train on inference trajectories and final answers, and then discarding parts of the trajectories based on specific strategies, the Dualformer model can imitate slow thinking while taking shortcuts like fast thinking.
This results in a more concise chain of thought (CoT).
Judging from the results, in slow thinking mode, Dualformer’s optimal solution rate reached 97.6%, and the reasoning steps were reduced by 45.5%.
Under automatic switching between fast and slow thinking modes, the optimal rate also reaches 96.6%, and the reasoning steps are reduced by 59.9%.
o1 has made System 2 (slow thinking) popular, which can greatly improve the reasoning ability of large models.
But the computational cost that comes with it is higher.
Dualformer can alleviate this problem by combining fast and slow thinking.
It builds on the work of Searchformer. Searchformer is a model that can solve complex reasoning tasks. It is trained on the paths generated by the A* search algorithm. It performs well on path planning tasks (such as mazes and push box games) and can find optimal solutions with higher efficiency.
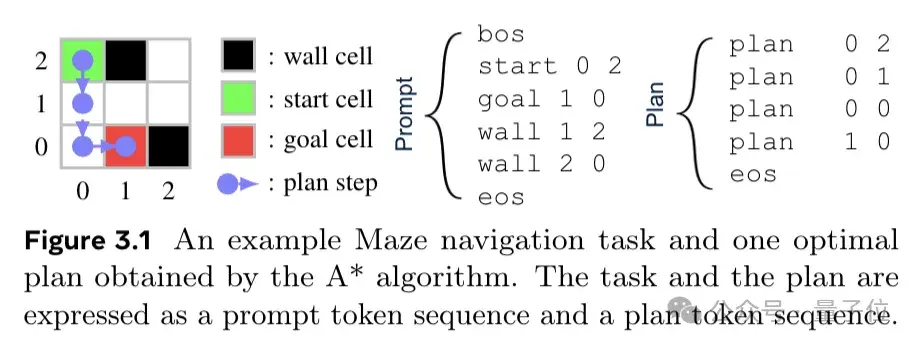
Research has found that humans tend to take shortcuts in their thinking processes. In order to further simulate humans, Dualformer is trained on random inference trajectory data and discards partial structures according to a customized discarding strategy during the training process.
For example, when dealing with path planning tasks, four levels of discarding strategies are designed based on different clauses in the search trajectory (such as close clauses, cost tokens in clauses, create clauses, etc.), ranging from discarding only the close clause to The entire trajectory is discarded and these policies are randomly selected to be applied during training.

Based on these strategies, Dualformer can learn a more concise and effective search and reasoning process.
During the inference phase, Dualformer can be configured in fast mode (outputs only the solution), slow mode (outputs the inference chain and final solution), or automatic mode (determines the inference mode on its own).
This flexible reasoning mode design enables the model to be adaptively adjusted according to different task requirements and scenarios, similar to how the human mind makes decisions in different situations.
Regarding specific tasks, the study set up a maze (Maze) and a pushing box game (Sokoban) to allow the model to perform path planning. and mathematical reasoning tasks.
In comparison, in the maze task, the paths output by the o1-preview and o1-mini models are not good and will “pass through the wall”.

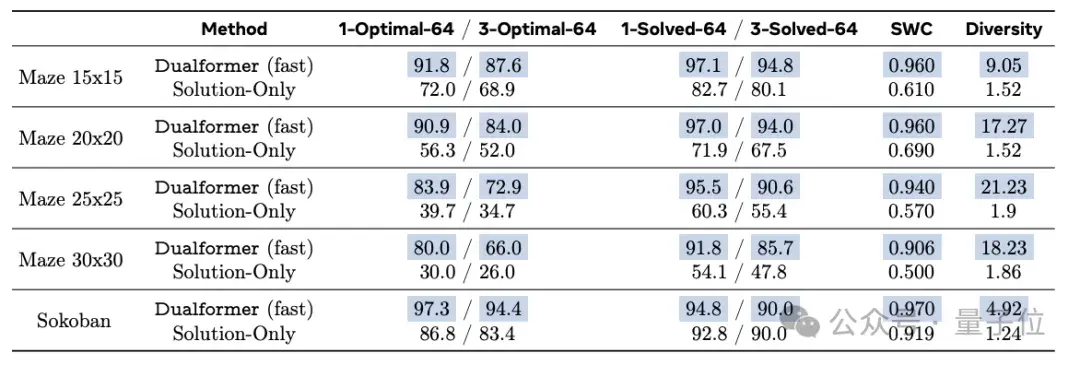
In fast thinking mode, the performance of Dualformer is as follows.
Dualformer completed these tasks with an optimal rate of 80%, significantly better than the Solution-Only model trained only on solution data, which achieved an optimal rate of only 30%.
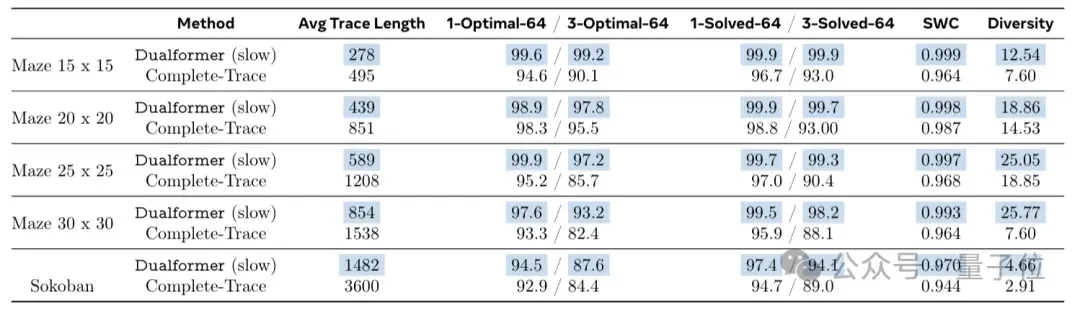
Slow thinking mode manifests itself as follows.
In the 30×30 maze task, the optimal solution can be achieved in 97.6% of cases, while the reasoning steps are reduced by 45.5%.
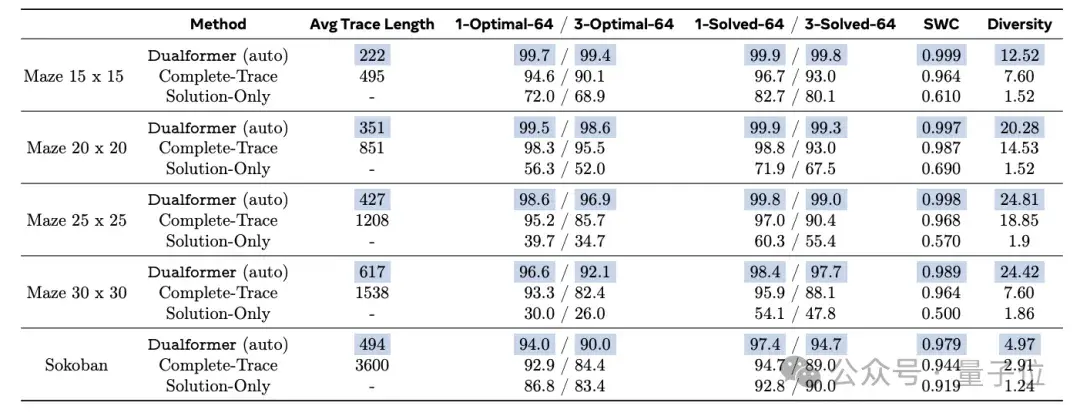
Under automatic switching between fast and slow thinking modes, the optimal rate of Dualformer reaches 96.6%, and compared with Searchformer, the number of reasoning steps is reduced by 59.9%.
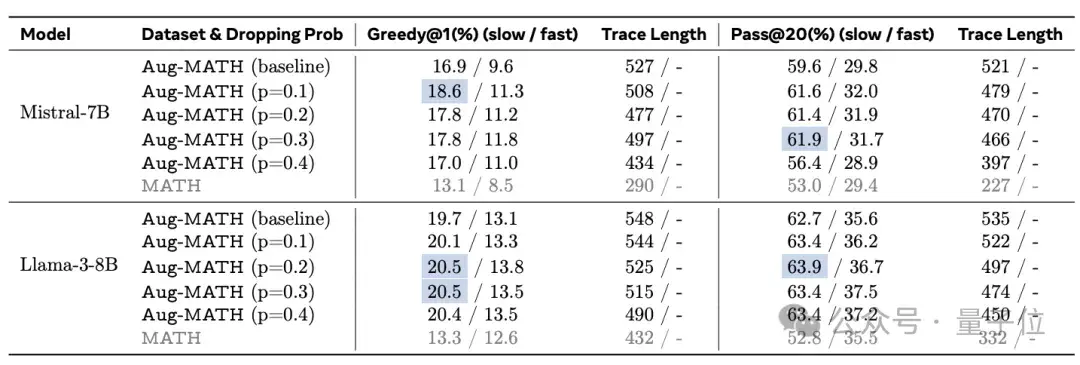
This method was extended to Mistral-7B and Llama3-8B, and the performance of the model was improved on the Aug-MATH data set.
For example, on the Mistral-7B model, when p=0.1, 0.2 and 0.3, the baseline model of Pass@20 metric, the absolute accuracy rate increases to 61.9%.
Finally, a look at the research team lineup.
This research was brought by Tian Yuandong et al.
Tian Yuandong is now the director of research scientists at Meta FAIR, leading the LLM reasoning, planning and decision-making group.

Qinqing Zheng is an engineer at FAIR, and his research focuses on generative models and reinforcement learning. She graduated from Zhejiang University with a bachelor’s degree and studied for a doctorate at the University of Chicago. From 2017 to 2019, he worked as a research scientist at Facebook and helped Facebook establish a distributed training system for advertising recommendation models.

Sainbayar Sukhbaatar is a research scientist at FAIR, mainly responsible for research on large model reasoning and memory. He has worked at Google, DeepMind, and Meta.

Michael Rabbat is one of the founding members of FAIR. Before joining Meta, he was a professor in the Department of Computer Engineering at McGill University. Research areas include machine learning, distributed algorithms, signal processing, etc.

Paper address:
All rights reserved. Any reproduction or use in any form without authorization is prohibited. Violators will be prosecuted.

