
We have known for some time that something is happening in this direction. We have a server here Milan-Xwhose L3 cache is increased by the V-cache. A similarly featured player-focused Ryzen 7 5800X3D is launched on the desktop this week. In the graphics segment, AMD implemented Infinity Cache, which will reach the main silicon in separate smaller chipsets at the end of this year for larger GPUs. But various sketchy reports suggest that this will not be the end either, and big changes are yet to come.
APU – SLC (System Level Cache)
After a long time, we can hear again about SLC or Infinity Cache unified for GPU and CPU part of APU. This idea makes good sense – if a larger cache is implemented in the chip, it is advantageous that it can be used by both processor and graphics cores. In addition, there are a number of tasks in which most of the workload is only the CPU or only the graphics part – and in such cases the busy part will have practically the entire cache for itself.
SLC is talked about in connection with the APU Phoenixwhich will be next connection said connection Zen 4 a RDNA 2. Phoenix should significantly increase graphics performance again. Existing Rembrandt has 12 CU (768 stream-processors) and Phoenix should offer them according to one source 16+ (1024), according to another 16-24 (1024-1536). So it seems quite safe to talk about ~ 50% increase in performance. Such a solution would benefit from a larger graphics cache, on the other hand, it would not be absolutely necessary.
This is perhaps the reason why some sources (albeit minority) talk about SLC only in connection with the APU Strix Point (Zen 5). This may be the approach of AMD, which implements many new products gradually and in such a way that the product can be released without them. See for example V-cache for Zen 3 – The processors were designed from the beginning to be able to use it, but on their own (or their release) was not dependent on the V-cache. It can be similar with SLC, which can show up with the Phoenix generation, but if its development is delayed, it can be released without it. We do not yet know whether this SLC would be implemented at the kernel level or optionally in the form of a V-cache.
V-cache instead of L3 for large processors
The current concept, where processor chipsets are equipped with L3 cache and others can be implemented via V-cache, does not seem to be a goal for AMD, but a technological transition. It allows, as already mentioned, to release a functional product regardless of whether the new technology is fine-tuned, and at the same time to implement the new technology into practice and with its help to create a new product. Zen 3 with V-cache seems to be the first step in this process. Another is captured in a diagram that has been circulating on the Internet since last year, which captures the kernels Zen 4 without L3 caches, which are covered by L3 caches in the form of V-cache.
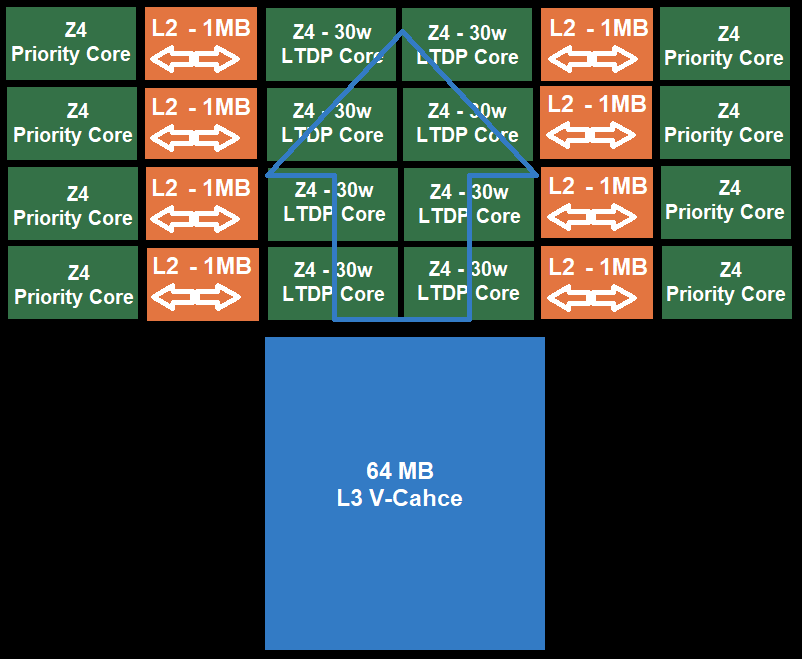
Because such a concept is not to be used on any key Zen 4 product (or Raphael for AM5 desktop or APU Phoenixani Epyc Genoa for servers), only the Epyc method remains Bergamo (128-core power-oriented solution). This product, which again is not necessary for the completion of the product portfolio, could theoretically serve as a test platform for implementing the idea of completely moving the L3 cache to the V-cache level.
The third – key – step then comes with the generation Zen 5. Not only that Zen 5 should have the standard L3 cache moved to the V-cache level (which allows you to save a significant amount of kernel, or to dedicate this area to the x86 kernel itself to increase IPC and at the same time solve the pain of new production processes that reduce SRAM less and less) to rework the L2 cache. It is currently 0.5MB (for Zen 3) or 1MB (for Zen 4) on each processor core. Thus, each kernel has its own small L2 cache – independent of the rest. Zen 5 will bring a unified L2 cache, where eight cores will be equipped with one large 8MB L2 cache. The advantage is similar to when Zen 3 AMD merged two L2 caches into one double. In situations where each core has a different cache capacity requirement, the performance of individual cores may not be limited by 1MB of L2 cache, but may use more. With a lower number of cores, up to multiples of the original capacity are available to individual cores. L2 cache Zen 5 in this respect it will be similar to the L3 cache Zen 3/4.
This change could be one of a number of elements that will lead to an intergenerational increase in IPC Zen 5. Until recently, it was reported to be around 25% above Zen 4but the latest information suggests that a value of around 30% above could be achieved Zen 4. This is still a value that is not a complete phantasmagoria and can be considered a realistically achievable goal.

If we look back, we can see that AMD is still succeeding in increasing the IPC with each new generation by 5% more than with the previous one – which obviously acts as a set goal. We must take into account that the 15% shift u Zen 2 it was not originally planned, because architecturally, Zen was supposed to be what it became Zen 2 (AMD did not have the resources and manpower to achieve the original goal at the time, so it decided Zen simplify and leave the original plan for Zen 2). Note, however, the increases in IPC:
- Zen 2: +15 %
- Zen 3: +19 %
- Zen 4: +~25%
- Zen 5: +~30%(?)
Of course, the IPC shifts cannot be increased indefinitely, but it seems that the increase in intergenerational growth by a further 5% (percentage points) is not Zen 5 excluded.
Somewhat ambiguous information so far relates to the combination of cores Zen 5 a Zen 4. Some sources assume that the combination of architectures will only apply to the APU segment (the rest would be built purely on kernels Zen 5), others assume that the combination will also apply to the classic desktop. It must be acknowledged that the first option (combination only for APUs) would again fit in better with the strategy of implementing the news in such a way that, in the event of a problem, key products would be affected as little as possible (recall that if it was with APUs) Strix Point problem and could not be released in time, it would not be a major setback, as at that time half of the mobile segment will already be covered by large processors with small integrated graphics).
Finally, we can get a rough illustrative overview of when we will see products with newly designed caches:
- Q2 2022 – Ryzen 7 5800X3D (V-cache v desktopu)
- Q4 2022 – RDNA 3 (chip Infinity Cache for larger GPUs)
- Q1 2023 – (first APU with SLC?)
- H1 2023 – Epyc Bergamo (theoretical possibility of moving L3 to V-cache)
- Q4 2023 – Zen 5 (unified L2 cache, L3 to V-cache transfer)
–


{kind=link}